The Shape of Vulnerability: How Adversarial Perturbations Reshape the Topology of Language Model Latent Spaces
Abstract
Adversarial perturbations in the context of large
language models (LLMs) are subtle changes
added to input data (i.e., images or text) that
are designed to alter predictions or outputs of
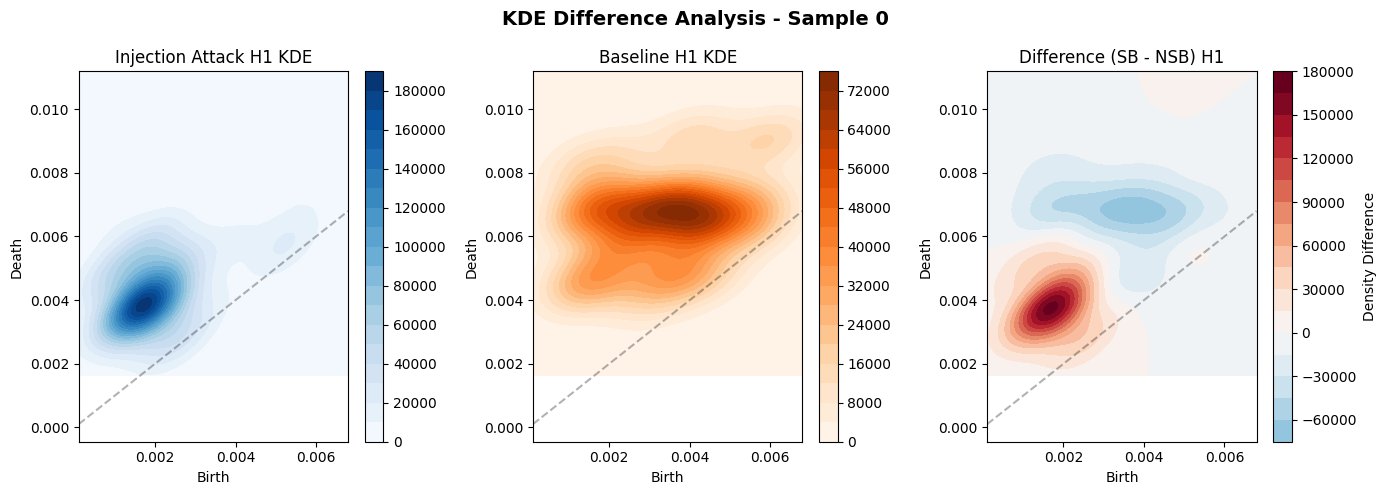
machine learning models. We introduce several
novel visualizations using topological data anal-
ysis (TDA) (leveraging persistent homology) to
characterize how adversarial perturbations act
on text inputs, specifically, how sandbagging
and code-injection attacks alter the geometric
structure of attention heads in transformer mod-
els. By computing persistent homology metrics
from attention maps across different model ar-
chitectures (such as BERT, RoBERTa, ELEC-
TRA, DistilGPT, etc.), we find that adversarial
inputs alter higher-dimensional topological fea-
tures (H1 loops and H2 voids) in ways that
distinguish them from clean, non-adversarial
inputs.