Using Topological Data Analysis to Characterize the Layers of Language Models Before and After Word Substitution Attacks
Abstract
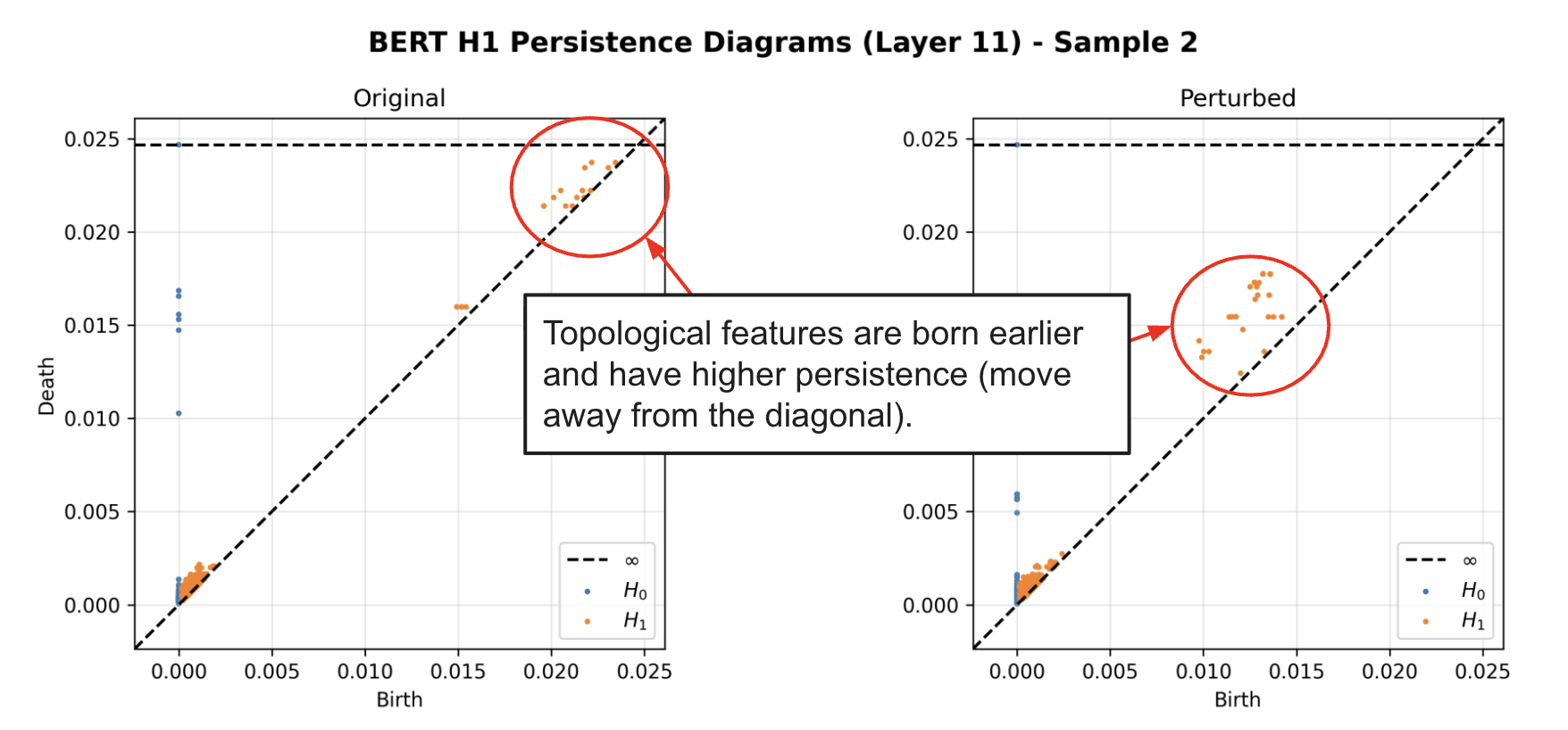
Large language models are known to be vulnerable to adversarial perturbations such as synonym-based word substitutions. However, previous analyses of adversarial influence focus only on output behavior and provide limited insight into the propagation of substitution-based input perturbations through internal representations. In this work, we introduce a topological data analysis (TDA) framework to study the structural effects of adversarial attacks on attention maps across model layers. We evaluate small encoder-based architectures (BERT, RoBERTa, DistilBERT) fine-tuned to solve binary classification on the IMDb review dataset, which were attacked using TextFooler. We convert attention maps into distance matrices and apply TDA to extract topological features, which we then compare using Wasserstein distances between original and perturbed features. In addition, we analyze these models on a layerby-layer basis. We find that adversarial perturbations induce systematic and statistically significant topological changes across layers, with the largest deviations occurring in late layers and smaller but notable effects in early layers. These patterns are consistent across models and are validated using both non-parametric (Kruskal–Wallis, Dunn) and parametric (oneway ANOVA, Tukey) tests on log-transformed Wasserstein distances. Our results demonstrate that TDA provides a robust and interpretable framework for evaluating how adversarial perturbations alter internal model structure, offering new insights into the layer-wise sensitivity of transformer-based models